Defination of big data architecture.
The logical and physical framework that governs how large amounts of data are ingested, processed, managed, stored, and accessible is referred to as big data architecture.
What is Big Data Architecture?
The basis for big data analytics is big data architecture. It is the overall framework for managing huge volumes of data in order to analyse it for business objectives, steering data analytics, and providing an environment in which big data analytics tools can extract important business insights from otherwise confusing data. The big data architectural framework acts as a design for big data infrastructures and solutions, logically outlining how big data solutions will operate, the components that will be employed, how information will flow, and security considerations.
Big data analytics architecture generally consists of four logical levels and conducts four primary processes:
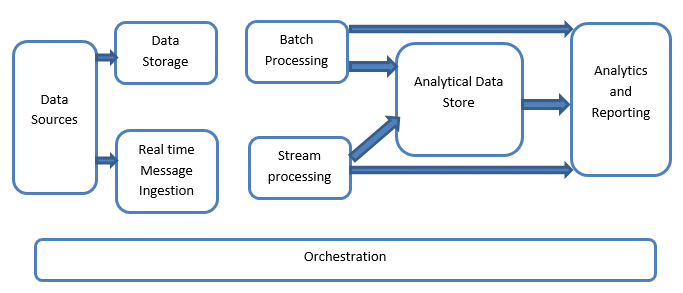
Layers of Big Data Architecture
- Big Data Sources Layer: A big data infrastructure can handle batch and runtime processing of big data sources including data warehouses, relational database management systems, SaaS applications, and Internet of Things devices.
- Management & Storage Layer: takes data from the source, transforms it to a format that the data analytics tool can understand, and stores it in that format.
- Data processing Layer: From the large data storage layer, analytics tools extract business insight.
- Consumption Layer: sends the findings of the big data analysis layer to the appropriate output layer, also known as the business analytics layer.
Processes of Big Data Architecture
- Connecting to Data Sources: Connectors and adapters may connect to a number of different storage systems, protocols, and networks, and can connect to any format of data.
- Data Governance: contains privacy and security requirements that operate from the time data is ingested through the time it is processed, analysed, stored, and deleted.
- Systems Management: The cornerstone for current big data architectures is generally highly scalable, large-scale distributed clusters, which must be monitored continuously by centralized control consoles.
- Defining Data Quality, Compliance Policies, and Ingestion Frequency and Sizes: The Quality of Service framework aids in the definition compliance policies, of data quality, and ingestion frequency.
You’ll need to invest in a big data infrastructure that can manage huge volumes of data to enjoy the benefits of big data.
These advantages include: improving big data comprehension and analysis, making better decisions faster, lowering costs, predicting future needs and trends, trying to encourage common standards by providing a common language, and provides quality approach to implementing technology that solves similar problems.
Big data infrastructure problems include data quality control, which necessitates in-depth research; scalability, which may be costly and slow down performance if not done correctly; and security, which becomes more complicated with large data sets.
Best Practices in Big Data Architecture
Creating big data architectural components before beginning a big data project is an important step in determining how the data will be utilised and how it will provide value to the company. Implementing the following big data architectural principles in your big data architecture plan will aid in the development of a service-oriented approach that guarantees data meets a wide range of business demands.
- First Step: A big data project should align with the business goal and include a thorough grasp of the organization’s context, major drivers, data architecture task needs, architecture principles and framework to be employed, and enterprise architecture maturity. Marketing strategies and organisational models, business principles and goals, current frameworks in use, governance and legal structures, IT strategy, and any pre-existing architecture structures and repositories are all key components of the present business technology environment to grasp.
- Data Sources: Sources of data should be identified and classified before any big data solution architecture is developed so that big data architects may efficiently normalise the data to a common format. Structured data, which is generally prepared using predetermined database procedures, and unstructured data, which does not follow a regular style, such as emails, pictures, and Internet data, are two types of data sources.
- Big Information Data should be aggregated into a single Master Data Management system for on-demand querying, either through batch or stream processing. Hadoop has been a popular batch processing platform for a long time. A data repository, such as a NoSQL-based or relational database management system, can be used to query the Master Data Management system.
- Data Services API: When selecting a database management system, think about whether there is a common query language, how to connect to the database, the database’s capacity to expand as data grows, and the safety procedures in place.
- User Interface Service: A big data proposed framework should have an excellent interface that is adaptable, accessible in the cloud, and usable through existing dashboards. Web Services for Remote Portlets (WSRP) specifications make it easier to serve Interface Design using Web Service calls.
Data processing layer
To clean, normalize, and transform data from multiple sources, data processing must touch every element to transforming data. After a record has been cleaned and finalized, the task is accomplished. This is significantly different from data access, which results in the same facts being obtained and accessed by multiple user applications repeatedly.
Because data processing is less of a barrier than data access when data volume is small, most data processing happens in the same dataset as the final data. As the volume of data grows, it’s become evident that data processing must be done outside of the database to avoid the overhead and limitations imposed by database systems that were not designed for large datasets in the first instance.
In the data storage and big data eras, and that was when ETL and subsequently Hadoop began to play a key role.
The problem with enormous data processing is that the amount of data to be processed is always more significant than the capacity of a hard disc but considerably less than the processing and computing RAM available at any one moment. Breaking data into smaller parts and processing them in parallel is the most basic method of effective data transmission.
To put it another way, execution is achieved by first enabling parallelization in the program development, so that as big data grows, the number of processing steps grows, while each process takes place to process the same quantity of data as before. Second, as the number of operations grows, more servers with more processing units, memory, and discs are decided to add.
The first parallel massive data processing was achieved using data partitioning techniques in database systems and ETL tools. Each partition of a dataset can be processed in parallel after it has been logically partitioned. HDFS (Highly Distributed File Systems) in Hadoop is a scaled version of the same concept. The data is divided into data blocks of the same size by HDFS. The blocks are then sent to other server nodes, recorded in the Names node’s meta-data store.
The number of data operations is defined by the number of data blocks and available budget (e.g., processors and memory) on every server node when a data process starts. As long as you have adequate CPUs and memory from several servers, HDFS can handle enormous parallel processing.
Spark has quickly grown in popularity as a fast engine for large-scale data computation in memory. Does this make sense to you? While memory has increased more affordable, it still costs more than hard discs. The amount of significant data to be handled in the big data domain is always considerably more than the memory space available.
So, how does Spark go about resolving the issue? First and foremost, in a distributed system with numerous data nodes, Spark uses the whole amount of RAM available. However, if any company tries to fit massive data into a Spark cluster, the quantity of RAM available is still insufficient and might be pricey. Let’s have a look at the kind of processing Spark is capable of. Reading data from disc to memory is always the first step in data processing, then writing the findings to discs. Spark will not outperform Hadoop if each record has to be processed once before being sent to disc, which is the case with most batch processing.
On the other hand, Spark can keep data in memory for many data transformation stages, but Hadoop cannot. This implies Spark is better at iteratively processing the same data numerous times, which is exactly what analytics and machine learning require. Consider the following scenario: How can you expand your analytics processing in a cost-effective method, given that there might be tens or hundreds of them running simultaneously?
Depending just on in-memory processing is insufficient, and distributed big data storage, such as Hadoop, remains an essential component of the big data solution, complementing Spark computing.
Stream processing is another favoured subject in the data processing world. It has a significant benefit in terms of computing speed reduction since it only needs to handle a limited quantity of data at any given moment. However, it lacks the flexibility of batch processing in two ways: the first is that the input data must be provided in a “stream” format, and the second is that some process logic that requires aggregating over periods must still be performed in batch.
Lastly Cloud-based solutions enable a more dynamic scaling of the decentralized processing system depending on data volume and, as a result, the number of parallel processes. This isn’t easy to do on-premises inside a business since new servers must be planned, budgeted, and acquired.
If capacity isn’t properly planned, large data processing may be restricted by the amount of hardware available, or additional purchases may result in resources that aren’t utilised. Processing on the cloud has a significant benefit in terms of infrastructure flexibility, which may ensure that optimal scalability is achieved more cost-effectively.