
Basics to JavaScript SEO: Full Guide 2023
The goal of SEO specialists should not be to become experts in JS; rather, they should anticipate developing a firm grasp on how web pages are read and rendered, which will enable them to view JS as a friend rather than an adversary on the road. This post’s purpose is to discuss optimizing content crawling and avoiding indexing issues.
SEO has the potential to work wonders for both website administrators and search engines, relieving the responsibilities placed on both sides. It is straightforward to increase search engine rankings if we provide content that is easily discoverable and interactive. As for technical SEO and JavaScript (JS), they both have a renaissance at the moment, whilst front-end development is in its prime.
JavaScript is used by the vast majority of online retailers in the United States to power their websites. The fact that these websites will load quickly regardless of the code execution process will be accessible to those using older browsers, will allow for user interaction, and will improve the overall user experience is crucial to remember. As a result, crawling activities are made more difficult by JavaScript, which usually results in lower ranks or even the inability to index a page. Googlebot will be unable to effectively parse a website if there is even a single code error.
A Brief Introduction to Modern JavaScript applied to SEO
If you’re not familiar with front-end development, JavaScript is a render programming language that is currently utilized for animation through the usage of what are known as SOM methods. As a novice to front-end development, using frameworks such as React and Vue, it may be utilized to construct native web applications in a more advanced form. While React and Vue are becoming increasingly popular, as an SEO professional, you’re more likely to encounter older structures such as WordPress, which uses Vanilla and jQuery as their foundation. To be more specific, JavaScript is primarily utilized in such content management systems to make slideshow, accordions, and other sorts of text animations, among other things.
What is JavaScript SEO?
A subset of Technical SEO (Search Engine Optimization) called JavaScript SEO is all about making JavaScript-heavy websites easier to crawl and index and also more search engine friendly. We want to make these websites more visible to people who use search engines and to make them rise in their rankings of them.
Is JavaScript harmful to SEO, or is JavaScript evil in nature? Definitely not. The process is a little different from what many SEOs are used to, and there is a learning curve to contend with. Even if it has the unfortunate reputation of being excessively used in situations where there is clearly a better solution, sometimes you just have to make do with what you’ve got. It’s important to remember that JavaScript is not without its shortcomings and that it’s not always the greatest tool for the task. It cannot be parsed in a progressive manner, unlike HTML and CSS, and as a result, it may be resource heavy in terms of page load time and performance. That is often done at the expense of performance.
Is JavaScript good or bad for SEO?
As a matter of fact, JavaScript is neither superior nor inferior at its root; it all depends on how you choose to employ it.
Most of your users have poor connectivity, so you should have a JavaScript website that can function properly even if they are not connected. In any case, whether you are running a news blog, a traffic blog, or anything else where every second counts, having a loading time of more than a couple of minutes is harmful to your visitors.
You can provide valuable feedback to JavaScript developers if you have a thorough understanding of how it works. It is imperative to the success of your website that it is optimized for both search engines and end users.
How does JavaScript affect SEO?
JavaScript has the potential to have an impact on the following critical on-page elements and ranking indicators for search engine optimization:
- Rendered content
- Links
- Lazy-loaded images
- Page load times
- Metadata
How does Google deal with JavaScript sites?
Understanding how JavaScript affects SEO begins with an understanding of what happens when the GoogleBot examines a web page, which is described below:
- Crawl
- Render
- Index

- The HTML is first downloaded by Googlebot.
- Googlebot can’t get to any links because JavaScript is there.
- There are two types of files that Googlebot downloads: JS and CSS. The JS and CSS files are then sent to Google’s Web Rendering Service.
- WRS goes through the resources and stores the information it finds in a list.
- Caffeine, Google’s indexer, crawls the page and adds it to the site.
- It lets Google bots find new pages because links are added to the crawling queue.
How to see if a website is built with JavaScript
When you use a tool like BuiltWith or Wappalyzer to look up technology, you can quickly see whether a website is built on a JavaScript framework. That is very useful. Use the “View Source” or “Inspect Element” tools in your web browser to look for JS code in the source code of a web page for more help. There are a lot of well-known JavaScript frameworks, like the ones on this list:
Angular by Google
React by Facebook
Vue by Evan You
Rendering options
After this discussion, it should be clear that client-side rendering, which only lets the client (like a browser or a crawler) run JavaScript code, has a bad effect on the crawling, indexing, and ranking process.
However, in addition to the JavaScript SEO best practices outlined above, there are other things you can do to make sure that JavaScript does not hurt your SEO performance.
It’s not in the scope of this article to go over all of the different rendering options that are out there (for example, pre-rendering). Because of this, we’ll go over the most common ways to make your site look better for search engines and users:
- Server-side rendering
- Dynamic rendering
Server-side rendering
That means that web pages are rendered on the server before they’re sent to the client (browser or crawler) rather than on the client itself. It is also called rendering on the client’s side or “client-side rendering.”
If you’re a visitor or a robot like Googlebot, both of these things are treated the same way. After the first load, you can use JavaScript code, and it will be run.
Pros:
- During the first HTML response, each and every thing that is important to search engines is there.
- It lets you load your First Contentful Paint quickly (“FCP”).
Cons:
- Slow “Time to First Byte” (TTFB) because the server needs to make web pages that look different every time.
Dynamic Rendering
Dynamic Rendering is the method by which a server answers in a different way based on who made the request in the first place. When a crawler examines a website, the server renders the HTML and returns it to the client; however, when a visitor accesses a page, the visitor must rely on client-side rendering to complete their task.
This rendering option is a quick fix and should only be used as a last resort in extreme circumstances. However, Google does not consider dynamic rendering to be cloaking (opens in a new tab) as long as the dynamic rendering generates identical information for both types of queries.
Pros:
- As soon as a search engine crawler asks for a page, the first HTML answer they get includes every element that the search engine cares about.
- Most of the time, it’s easier and faster to do something.
Cons:
- It complicates debugging issues.
What about social media crawlers?
Social media crawlers, like those from Twitter, Facebook, LinkedIn, and Slack, also need simple HTML access in order to get useful information.
There must be a way to find the page’s OpenGraph or Twitter Card markup, or there must not be any. If they can’t find them, they won’t be able to make a snippet with the page title and meta description in it. So, your snippet will look unprofessional, and you won’t get much attention from these social networks.
JavaScript SEO for core content
For example, consider the following: Angular, React, and Vue are some of the JavaScript frameworks that are used to build today’s internet applications. JavaScript frameworks make it possible for developers to quickly and simply design and grow interactive online applications. Consider the Angular.js project template that comes with the framework. Angular.js is a prominent framework created by Google that is used by many developers.
The appearance of this page, when viewed in a browser, is that of a typical web page. We have the ability to view text, photographs, and hyperlinks on the page. Take a closer look at the code from the inside out, however.

As we can see, this HTML document is almost completely empty of anything that is worth reading. A few script tags are the only things in the body of the page. That is because JavaScript is used to put the main content of the application into the DOM. To put it another way, this app completely depends on JS to load important information on the page!
SEO problems could happen in the following ways: People need important information, but search engine robots don’t. That could be very difficult! If search engines can’t get through your whole page, your website could get lost in the shuffle. In the future, we’ll talk more in-depth about this.
JavaScript SEO for lazy-loading images
JavaScript can also impact the crawlability of lazy-loaded images. Here is a straightforward illustration. This code example demonstrates how to implement JavaScript’s lazy-loading of images in the Document Object Model (DOM):
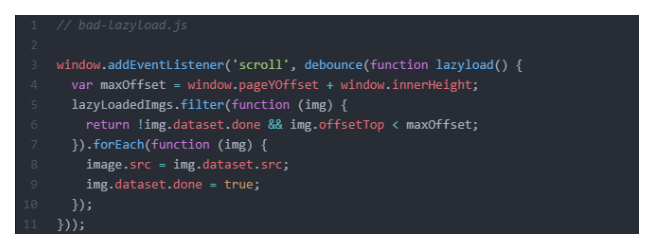
Googlebot can handle slow page loading, but it doesn’t “scroll” through your web pages in the same way that a human would. Instead, when Googlebot is looking at a website’s content, it just widens the virtual viewport that it is using. It means that the “scroll” event listener won’t work, and the crawler won’t show any content.
For example, consider this piece of code that is more SEO-friendly:

With the help of the IntersectionObserver API, you can learn how to receive notifications when an observed element becomes visible. On the other hand, it is more robust and customizable than the on-scroll event listener and is supported by the most recent version of Googlebot. This code works because when Googlebot “sees” your content, the viewport of the bot is enlarged to accommodate it.
Real-world application: JavaScript SEO for eCommerce
eCommerce websites are a real-world example of dynamic content injection in JavaScript, which may be found in many places. For example, online shops typically utilize JavaScript to load products onto category pages, which can be very time-consuming.
When used in conjunction with JavaScript, eCommerce websites can dynamically update the products displayed on their category pages. That makes sense, given that their inventory is constantly changing as a result of customer purchases. Is Google, on the other hand, able to “see” your content if your JS files aren’t being executed?
For eCommerce businesses that rely on online conversions, not having their products indexed by Google could spell disaster for their business.
How to test and rectify JavaScript SEO issues
Here are a few steps to follow right now to find out if you’re having problems with JavaScript SEO:
- Make use of Google’s Webmaster Tools to get a picture of the page. That way, you can look at a website from Google’s point of view instead of your own.
- Site search lets you look up information in Google’s database. There is a way to make sure that all of your JavaScript content is being properly indexed by Google. You can do this by going to Google and looking through their index.
- Debugging can be done with the help of Chrome’s built-in developer tools. Use the source code and the rendered code to compare what Google sees and what people see. Make sure they are almost the same.
How to fix JavaScript rendering issues
Now you would be thinking, how to solve this issue? It can be solved with the help of universal JavaScript or else commonly known as Isomorphic JavaScript. And why is that, you ask? Because Isomorphic JavaScript can run on the server side also and client side also.
When compared to client-side rendering, there are some JavaScript solutions that are more search-friendly since they avoid transferring JS to both users and crawlers:
Server-side rendering:- This means that for each request, JS is executed on the server. SSR can be implemented using a Node.js library such as Puppeteer. That, however, might place a significant amount of demand on the server.
Hybrid rendering:- As the name suggests, it is hybrid; it is a combination of both the side server as well as the client side. The core content is sent to the server side first before it goes to the client side.
Dynamic rendering: In this solution, the server determines the user agent used by the client. It can then transmit pre-rendered JavaScript material, such as search engine results, to the public. Any extra user agents that wish to display their material must do so on the client side. In the case of Google Webmasters, for example, the use of Renderton, a popular open-source solution for dynamic rendering, is recommended.
It’s because of the strategies above that search engine bots get fully rendered copies of web pages when they ask to crawl HTML resources. However, once the web infrastructure is in place, many of these can be very difficult, if not impossible, to do. To do this, you need to think about JavaScript SEO best practices when you make your next online app or site.
Wrapping it up
JavaScript is a difficult subject to understand from a front-end viewpoint, and it is even more difficult to understand when it comes to SEO for its applications. Unfortunately, JavaScript is currently used by more than 90 percent of the internet’s websites, and most websites combine at least five scripts into their programming. In an industry that is always evolving, such as SEO, it is vital to recognize the importance of being able to monitor and review the JavaScript on your website.